最近在学习 LLM Agent,但终觉“纸上学来终觉浅,绝知此事要躬行”,所以想写个小项目试试手。在这个人均写一个 Manus 的时代,在这个半开卷的情况下,况且 Manus 的提词已经泄漏的情况下,是不是我也可以写一个,我整理了一下自己的需求如下:
- 可单主机云上部署,好部署在我家里的 Server 上。
- 集成浏览器、Shell、Python、Node 等工具及 Ubuntu 沙盒环境,每一个任务分配一个沙盒。
- Web UI 与提示词直接借鉴官方 Manus 的。
结合 Cursor 应该可以快速地写出一个 Manus 的示例,听说 OpenManus 4 小时就写出来了。
项目地址:https://github.com/Simpleyyt/ai-manus
Demo 演示
Code USE
Prompt:写一个复杂的 python 示例
原始链接:https://github.com/user-attachments/assets/5cb2240b-0984-4db0-8818-a24f81624b04
Browser Use
Prompt: 任务:llm 最新论文
原始链接:https://github.com/user-attachments/assets/8f7788a4-fbda-49f5-b836-949a607c64ac
效果可以说是相当的凑合,但是目前是学习目的,提示词与 Agent 流程可能都需要优化一下,懒得再调了,就交给广大网友了。
整体设计
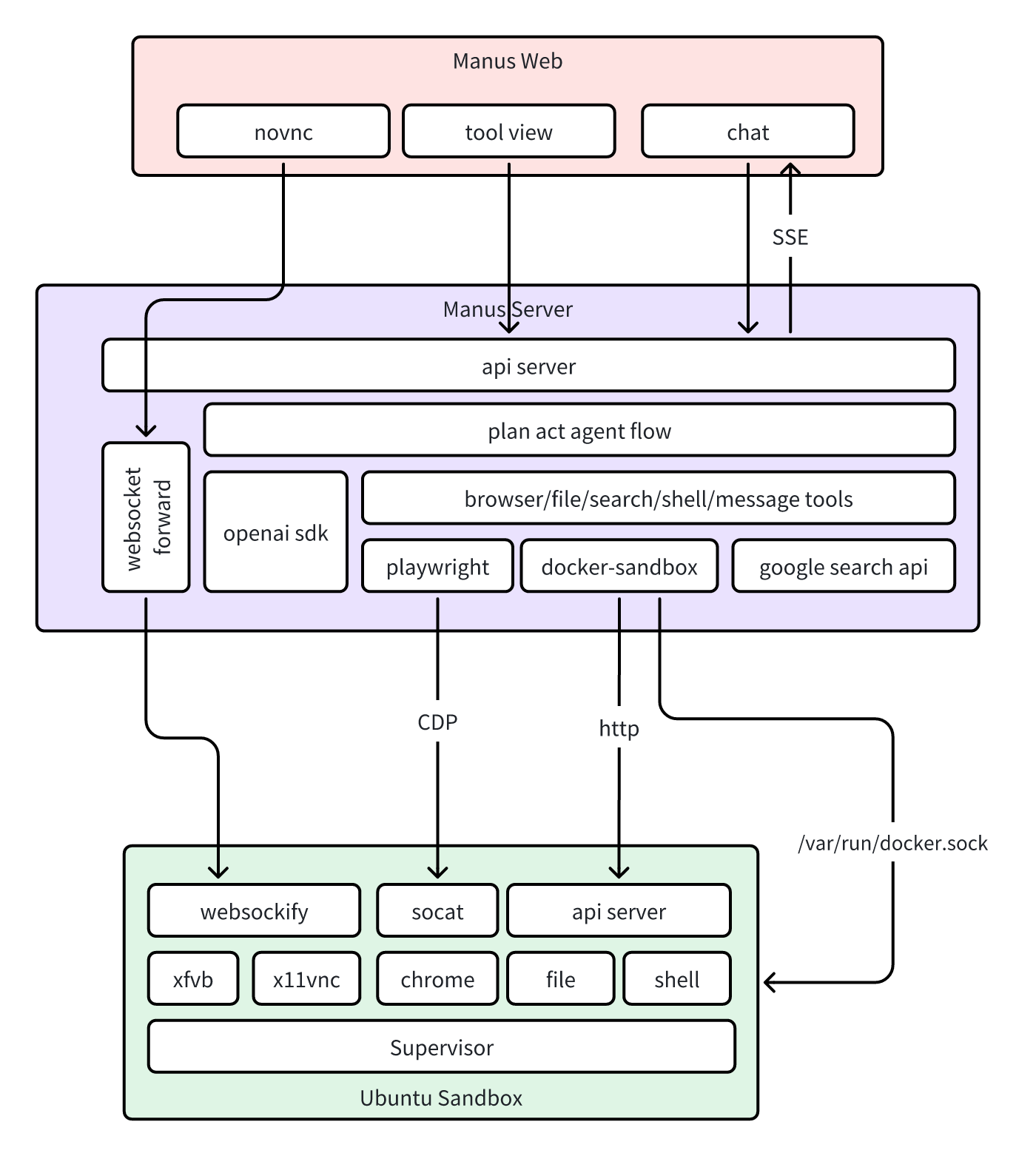
整体系统由三个模块组成:Web、Server 与 Sandbox,用户使用流程如下:
当用户发起对话时:
- Web 向 Server 发送创建 Agent 请求,Server 通过
/var/run/docker.sock创建出 Sandbox,并返回会话 ID。 - Sandbox 是一个 Ubuntu Docker 环境,里面会启动 chrome 浏览器及 File/Shell 等工具的 API 服务。
- Web 往会话 ID 中发送用户消息,Server 收到用户消息后,将消息发送给 PlanAct Agent 处理。
- PlanAct Agent 处理过程中会调用相关工具完成任务。
- Agent 处理过程中产生的所有事件通过 SSE 发回 Web。
当用户浏览工具时:
- 浏览器:
- Sandbox 的无头浏览器通过 xvfb 与 x11vnc 启动了 vnc 服务,并且通过 websockify 将 vnc 转化成 websocket。
- Web 的 NoVNC 组件通过 Server 的 Websocket Forward 转发到 Sandbox,实现浏览器查看。
- 其它工具:其它工具原理也是差不多。
AI Agent 设计模式
AI Agent 是什么?相信大家都听烂了,我在这里说的肯定不如别人说的好,简单来说就是:AI Agent = LLM + Planning + Memory + Tools。
FunctionCall or ReAct or LangChain?
先来说一下 Tool Use 部分,目前可以使用的方式是:1)高阶模型自身的 FunctionCall 能力;2)ReAct Prompt 框架;3)LangChain Agent 框架,其实它是前两者的高度封装。
最简单是使用 LangChain 这样高度封装的框架了,但是对于学习目的的项目来说,我一直强烈想知道它背后做了什么,所以这个先 Pass 掉了。
| 使用 FunctionCall 来使用工具要求比较高阶的模型,但 ReAct 的设计又太繁琐,思来想去,还是先使用 FunctionCall,先用好的模型开发,后面再来研究 ReAct 框架。关于 ReAct ,感兴趣可以看看:[ReAct 框架 | Prompt Engineering Guide](https://www.promptingguide.ai/zh/techniques/react)。 |

因此,该项目对 LLM 的要求如下:
- 兼容 OpenAI 接口
- 支持 FunctionCall
- 支持 Json 格式输出(因为抛弃了 LangChain 又想省事)
Plan-and-Act Agent 设计模式
整体使用 Plan-and-Act 的 Agent 设计模式,相关论文:Plan-and-Act : Improving Planning of Agents for Long-Horizon Tasks,它的相关流程如下:
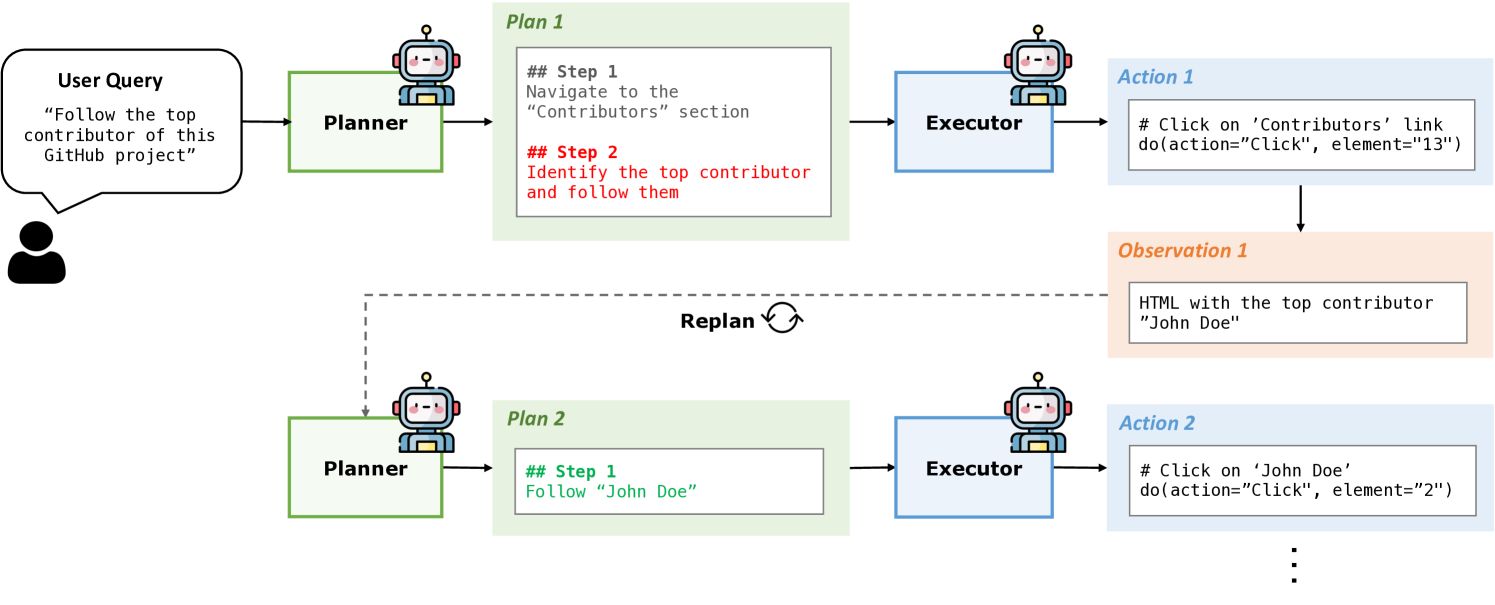
即将系统分成 Planner 和 Executor,Planner 将任务进行规划拆分,Executor 负责任务分步执行,将执行结果返回给 Planner 重新规划。
项目中的状态流转图如下:
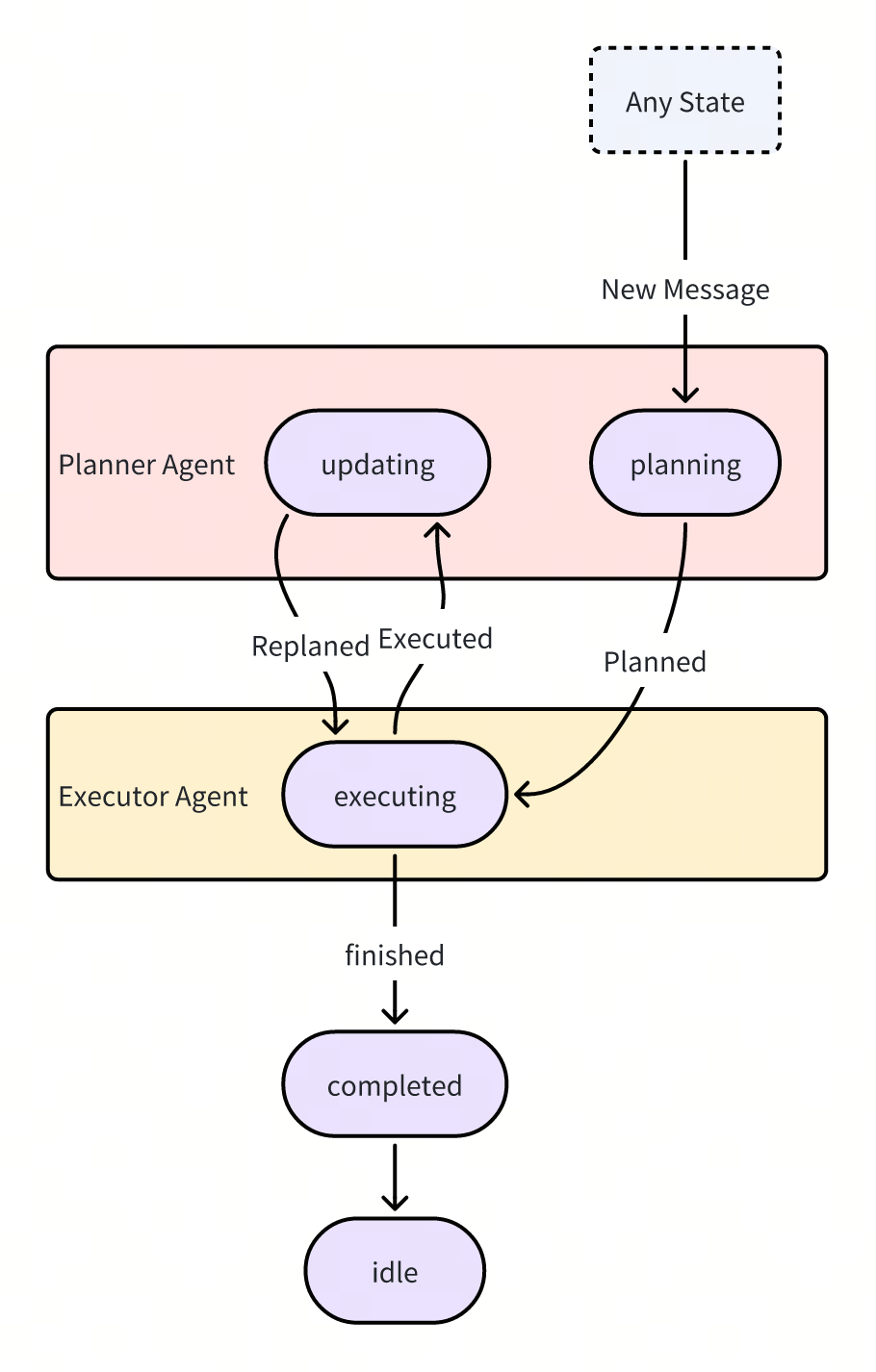
系统支持被打断,所有打断的消息都会流向 Planner Agent,Planner Agent 为根据用户的打断消息重新规划。
Sandbox 设计
为了实现每个任务使用单独的 Docker 沙盒,我们 Server 通过/var/run/docker.sock进行机器上 Docker 沙盒的创建与销毁。
Sandbox 进程与生命周期管理
整个 Sandbox 通过 supervisord 进程管理,并且通过 supervisord 实现 Sandbox 的 TTL 管理。因为 Agent 目前没有主动销毁机制,所以需要 Sandbox 自动过期自销毁,并实现续时等接口。
File & Shell 工具
文件操作与 Shell 命令执行没有什么难度,Cursor 最擅长这些,我把 Manus 的工具描述丢给 Cursor 后,很快就用 FastAPI 帮我生成了一整套代码,不得不说很稳定,基本没有怎么改过。
Browser 工具
目前遍地的 Manus 都在使用 browser-use(https://github.com/browser-use/browser-use)这个库,为了学习和研究的目的,我还是决定使用 Playwright + Chrome 自己搞一个。由于目前还没有能力使用视觉模型,所以还是以文字模型为基础来操作浏览器。
为了让 Sandbox 更加纯粹,Sandbox 只启动 Chrome,并且暴露 CDP 和 VNC 让 Server 来操作。
启动 Browser
坑点一:启动参数
Chrome browser 的启动有很多参数,遇到问题再找参数有点费时费力,直接站在巨人的肩膀上,参考 browser-use 的启动参数:https://github.com/browser-use/browser-use/blob/main/browser_use/browser/chrome.py。
坑点二:CDP 监听地址不支持0.0.0.0
新版本 Chrome 似乎已经不支持--remote-debugging-address参数(参考:https://issues.chromium.org/issues/327558594),解决方案可以通过端口转发:
# 假设 CDP 监听在 127.0.0.1:8222
socat TCP-LISTEN:9222,bind=0.0.0.0,fork,reuseaddr TCP:127.0.0.1:8222
坑点三:CDP 地址不能通过域名访问
即 Http Header 的 Host 字段只能是 IP 或者 localhost,只需要在反向代理中把相关字段给替换掉即可。
VNC 访问
由于 Docker 镜像内没有 X Server 等图形环境,所有通过虚拟 X11 显示服务器Xvfb来给 Chrome 绘制窗口,并通过x11vnc提供 VNC Server:
# 启动 Xvfb 在 Display :1
Xvfb :1 -screen 0 1280x1029x24
# Chrome 浏览器指定 Display
google-chrome \
--display=:1 \
...
# 启动 VNC 服务
x11vnc -display :1 -nopw -listen 0.0.0.0 -xkb -forever -rfbport 5900
由于 VNC 的四层端口对反向代理转发不友好,所以这里还使用websockify将 VNC 转成七层Websocket:
# 将暴露 5901 端口 Websocket 服务
websockify 0.0.0.0:5901 localhost:5900
以便于后面NoVNC连接。
AI 网页元素操作与信息提取
一开始天真地把整个 html 丢给大模型,发现是行不通的,一丢过去就爆 Token 了。小调研了一下,发现现在主流的做法是:1)可交互元素提取;2)网页信息提取。
首先是提取可见的、可交互的元素,以便让大模型识别哪些可以输入、点击等。一般将元素提取成index <tag>text</tag>,例如:
1 <input>手机号</input>
2 <input>密码</input>
3 <button>确认</button>
...
并在原标签中把 ID 号标注上去,这里是 Cursor 给我生成的代码,我也没有细看,但它能 work:
1 | |
这样大模型就可以根据 ID 号来操作元素了。
还要进行网页信息提取,目前主流做法是先去掉不可见元素后,先转成 markdown,再给大模型进行提取,以节省 Token,如下:
1 | |
至此,大模型就可以与网页交互与阅读网页信息内容了。
Web UI 设计
Web UI 编写虽然属于我的软肋,但属于 Cursor 的强项,结合对正版 Manus 的借鉴也可以搞得七七八八,页面比较简单。
如何部署?
环境要求
本项目主要依赖 Docker 进行开发与部署,需要安装较新版本的 Docker:
- Docker 20.10+
- Docker Compose
模型能力也是要求比较高:
- 兼容 OpenAI 接口
- 支持 FunctionCall
- 支持 Json Format 输出
推荐 Deepseek 与 ChatGPT。
部署
推荐使用 Docker Compose 进行部署,
1 | |
如何开发?
环境准备
环境要求在部署章节已经做了说明。
下载项目:
git clone https://github.com/Simpleyyt/ai-manus.git
cd ai-manus
复制配置文件:
cp .env.example .env
修改配置文件:
1 | |
开发
开发模式下只会全局启动一个沙盒。
运行调试:
# 相当于 docker compose -f docker-compose-development.yaml up
./dev.sh up
Web、Sandbox、Server 都会以 reload 模式运行,即代码改动会自动 reload。暴露的端口如下:
- 5173: Web 前端端口。
- 8000: Server API 服务端口。
- 8080: Sandbox API 服务端口。
- 5900: Sandbox VNC 端口。
- 9222: Sandbox Chrome 浏览器 CDP 端口。
当依赖变化时,即requirements.txt或者package.json变化时,可以清理并重新构建一下:
# 清理掉所有相关资源
./dev.sh down -v
# 重新构建镜像
./dev.sh build
# 调试运行
./dev.sh up
发布
export IMAGE_REGISTRY=xxxx
export IMAGE_TAG=latest
# 构建镜像
./run build
# 推送到相应的镜像仓库
./run push
写在最后
本项目主要用于学习与研究目的,共同学习和进步,也是代码工程师未来跃变提词工程师做点准备。